Shapley Values (shap)
Shapley Values (shap)
Shapley values는 모델이 예측한 값이 평균과 비교했을 때 어떤 변수들이 감소 또는 증가하도록 기여했는지(회귀, 0 ~ 1 사이의 확률에서 감소 또는 증가하도록 기여했다면 분류) 계산하는 방법이다.
기여도 계산
기여도를 계산하는 방법은 기여도 계산을 원하는 변수를 제외한 모든 feature들의 포함여부에 따라 모든 경우의 수를 뽑고 각각의 경우의 수에 대해서 기여도 계산을 원하는 변수가 포함되었을 때와 포함되지 않았을 때의 예측값의 차이를 계산한다. 이후 이 예측값들의 평균을 구한 것이 해당 변수가 모델이 예측한 값에 대한 기여도가 된다.
예를 들어, 아래와 같은 집값 계산 모델과 데이터가 있다고 가정해보자.

위와 같은 데이터에서 반려동물 허용 변수에 대해서 기여도를 알고 싶다면 나머지 변수들인 '공원근처, 면적, 층' 에 대해서 포함시키기도 하고 포함시키지 않기도 하면서 모든 조합을 구해 '반려동물허용' 변수가 포함된 8가지의 경우에서 각각의 '반려동물허용' 변수가 포함되지 않은 경우 8가지 예측값을 뺀다.

그렇다면 위처럼 공원근처=1, 면적=50, 층=2일때 반려동물허용이 예측값에 얼마나 기여하는지 값이 계산되는 것이다.
이런 과정을 각각의 변수마다 실행하고 각각의 행 데이터마다 실행한다.
계산식
shapley value의 계산식은 아래와 같다.

단순하게는 차이라고 얘기했지만 조합안의 feature의 개수에 따라 가중평균을 계산하여 shapley value가 도출된다.
간단하게 설명하자면 val은 예측값을 의미하고 S는 부분집합(xj가 없는 모든 집합중에서 뽑은) S는 부분집합, 절대값은 크기를 뜻하며 p는 모든 feature의 개수를 의미한다.
즉, 모든 부분집합에 대해서 우리가 원하는 feature를 포함시킨 경우의 예측값에서 포함시키지 않은 경우의 예측값을 빼고 그때의 부분집합 크기와 모든 feature의 수로 가중평균을 구하는 것이다.
코드
코드는 아래와 같다.
from sklearn.ensemble import RandomForestRegressor
import shap
model = RandomForestRegressor()
model.fit(x_train, y_train)
explainer1 = shap.TreeExplainer(model)
shap_values1 = explainer1.shap_values(x)위의 코드에서는 randomforest의 회귀모델로 실습했다.
순서는 다음과 같다.
shap 패키지에서 explainer 함수를 model과 함께 선언하고 shap_values 함수와 함께 x를 넣어주면 shapley values가 계산되어 나온다. -> shap values는 각 행 데이터마다 존재하고 그 데이터안에서 각 변수마다 존재하기 때문에 x의 shape과 동일할 것이다.
shap_values1.shape
x.shape
예를 들어 아래와 같은 그래프에서 이상치에 대해서 조사해본다고 가정해보자.
각각의 점들은 데이터에서 371, 266, 505, 214의 index를 가진다.
plt.figure(figsize = (10,6))
sns.scatterplot(x='lstat', y = 'medv', data = data)
sns.scatterplot(x='lstat', y = 'medv', data = data.iloc[[371]], color = 'r')
plt.text(10.5, 49.6, '371(9.53, 50)', color = 'r')
sns.scatterplot(x='lstat', y = 'medv', data = data.iloc[[266]], color = 'r')
plt.text(15.5, 30.2, '266(14.79, 30.7)', color = 'r')
sns.scatterplot(x='lstat', y = 'medv', data = data.iloc[[505]], color = 'r')
plt.text(8.5, 11.5, '505(7.88, 11.9)', color = 'r')
sns.scatterplot(x='lstat', y = 'medv', data = data.iloc[[214]], color = 'r')
plt.text(30.2, 23.3, '214(29.55, 23.7)', color = 'r')
plt.grid()
plt.show()
총 4개의 데이터 중에서 2개만을 가져와봤다.
shap.initjs()
shap.force_plot(explainer1.expected_value, shap_values1[371, :], x.iloc[371,:])
shap.initjs()
shap.force_plot(explainer1.expected_value, shap_values1[505, :], x.iloc[505,:])
먼저 'shap.initjs()'는 javascript를 사용해 그래프를 그려야하기 때문에 javascript를 사용하기 위한 코드이다.
다음으로 shap의 force_plot을 사용해서 행데이터를 기준으로 데이터들이 갖는 평균 예측값(explainer의 expected value)을 넣어주고 해당 행 데이터(위에서 말한 이상치 데이터)의 shapley value와 실제 feature의 데이터(x)를 넣어준다.
그래프를 보면 빨간색 선들은 예측값이 증가하도록 기여한 값들이고 파란색 선들은 예측값이 감소하도록 기여한 feature들이다. 그중에서 예측값의 가장 근처에 있는 값들은 증가 또는 감소에 가장 크게 기여한 값들이다.
코드 +
아래의 summary_plot이라는 메서드를 통해 모든 변수의 shapley value를 확인해볼 수 있으며 shapley value가 증가에 기여하는지 감소에 기여하는지 알 수 있다.
shap.summary_plot(shap_values1, x_train)
가장 영향력이 커 가장 상단에 위치해있는 lstat(하위 계층 비율)을 살펴보면 feature value가 클수록 shapley value가 작은 것을 알 수 있다. 즉, lstat의 비율이 클수록 집값이 하락하는 방향으로 영향을 준다는 뜻이다.
또한 아래와 같이 하나의 행데이터에 대해서 shapely value를 알아보는 것이 아니라 모든 변수에 대해서 실행하게 되면 각 변수들 그리고 다양한 옵션으로 기여도를 관찰할 수 있다.
shap.initjs()
shap.force_plot(explainer1.expected_value, shap_values1, x_train)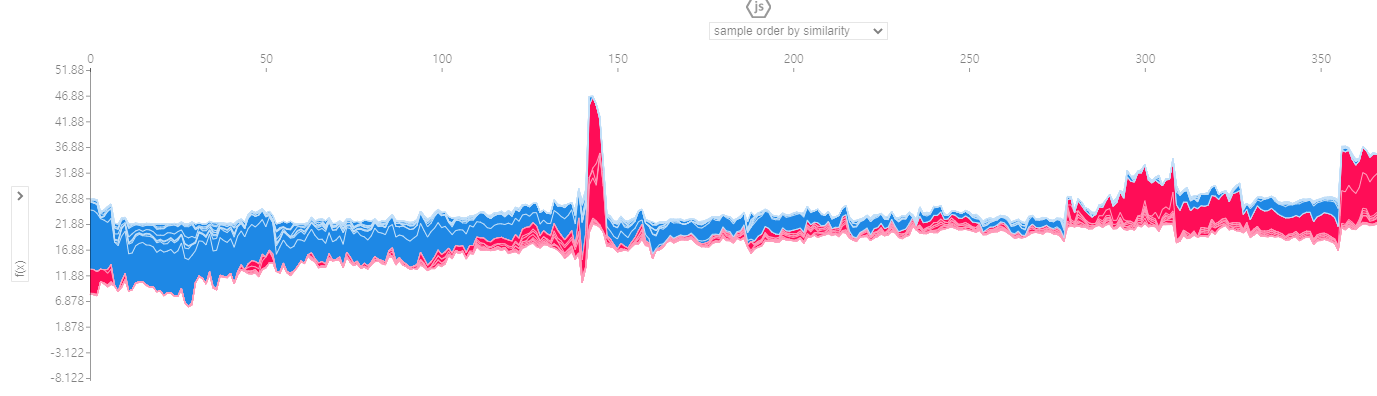
마지막으로 아래의 dependence_plot 함수를 사용하면 각 변수의 shapley value와 실제 feature값의 분포와 관계를 확인할 수 있다. 또한 interaction_index 옵션으로 다른 변수와의 관계도 같이 볼 수 있다.
shap.dependence_plot('lstat', shap_values1, x_train)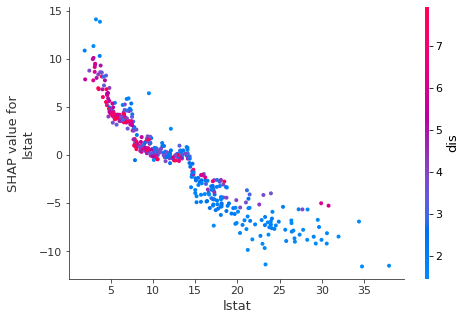
shap.dependence_plot('lstat', shap_values1, x_train, interaction_index = 'nox')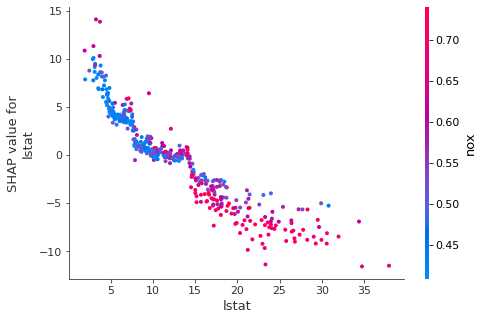
dependence plot은 interaction_index 때문에 해석하기 어려워 보이지만 색을 제외하고 관찰하면 쉽다.
위 그래프들을 분석해보자.
lstat가 높을 수록 lstat가 예측값을 감소시키는데 기여할 확률이 높아보인다. 즉, 추세를 보면 lstat가 높을수록 lstat는 예측값을 감소하도록 기여했고 lstat가 작을수록 예측값을 증가시키는데 기여했다고 볼 수 있다.
이때 점들의 색에 해당하는 interaction_index는 무엇이냐면..
lstat인 하위계층비율이 높은 곳일 수록 빨간점에 해당하는데 이는 nox(일산화질소비율)이 높다는 것으로 볼 수 있다.
interaction_index와 shap value는 따로따로 다른 그래프라고 인식하면 된다.
참고로 interaction_index는 default로 가장 관련이 있는 변수를 알아서 선택해준다. 사용자가 원하는 변수가 있다면 그때 interaction_index에 넣어주면 된다.
dependence plot 해석이 어렵다면 아래의 글을 읽어보자.
dependence plot 부분을 읽으면 어떻게 해석하는지 나와있다.
https://www.kaggle.com/code/dansbecker/advanced-uses-of-shap-values
Advanced Uses of SHAP Values
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
주의
shapley value를 구하기 위한 shap 라이브러리는 아직 개발중으로 모든 알고리즘 모델에 대해서 지원하지 않는다. 현재까지는 tree기반 모델, DL모델, kernel모델(SVM)만을 지원하고 있다.
게다가 explainer를 선언할 때는 각 모델에 맞게 함수를 사용해야 한다. tree기반의 모델을 사용하고 있다면 explainer를 선언할 때 TreeExplainer함수를 사용해야하고 DL 모델을 사용하고 있다면 DeepExplainer를 사용해야한다.
Reference
https://www.kaggle.com/code/dansbecker/advanced-uses-of-shap-values
Advanced Uses of SHAP Values
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
https://slundberg.github.io/shap/notebooks/plots/dependence_plot.html
dependence_plot
Documentation by example for shap.dependence_plot¶ This notebook is designed to demonstrate (and so document) how to use the shap.dependence_plot function. It uses an XGBoost model trained on the classic UCI adult income dataset (which is classification t
slundberg.github.io
https://datanetworkanalysis.github.io/2019/12/23/shap1
SHAP에 대한 모든 것 - part 1 : Shapley Values 알아보기
1. 게임이론 (Game Thoery) Shapley Value에 대해 알기위해서는 게임이론에 대해 먼저 이해해야한다. 게임이론이란 우리가 아는 게임을 말하는 것이 아닌 여러 주제가 서로 영향을 미치는 상황에서 서로
datanetworkanalysis.github.io