
1. 신경망 학습
신경망의 특징은 데이터를 보고 학습할 수 있다는 점이다. 여기서 학습은 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 찾고 갱신하는 과정을 말한다.
그럼 이 학습에 대해서 좀 더 알아보자.
1.0.1. 데이터 주도 학습
SVM, KNN과 같은 기계학습은 이미지에 포함된 중요한 특징을 사람이 직접 찾아내어 모델에 넣어줘야 하는 특징이 있다. 하지만 신경망은 입력 데이터만 정해주면 기계 자동으로 그 특징을 찾아낸다. 이런 신경망의 특성 때문에 딥러닝은 End-to-End Machine Learning(종단간 기계학습)이라고도 불린다.
1.0.2. 훈련 데이터와 시험 데이터
신경망에 적용되는 데이터는 훈련 데이터, 시험 데이터로 나뉘게 된다. 훈련 데이터는 말 그대로 모델의 학습을 위해 사용되는 데이터로 모델 안의 가중치 매개변수(parameter)를 갱신하는데 사용된다.
시험 데이터는 학습한 모델의 범용적 성능 (Generalization Performance)을 확인하기 위한 데이터이다. 모델이 훈련 데이터로 학습을 진행했다면 처음 보는 데이터인 시험 데이터에도 좋은 성능을 보이는지 확인하는 것이다.
참고로, 만약 훈련 데이터에는 최적화 되었지만 시험 데이터는 잘 맞추지 못하는 것을 오버피팅(overfitting), 과적합이라고 한다.
1.1. 손실 함수 (Loss Function)
손실 함수는 모델에 어떤 입력을 넣었을 때 해당 입력의 정답값을 기준으로 얼마나 차이가 나는지 확인할 수 있는 척도다.
손실 함수로 많이 쓰이는 함수는 MSE(평균 제곱 오차, Mean Squared Error), 교차 엔트로피 오차 (Cross Entropy Error) 등이 있다.

일반적으로 MSE는 회귀 문제에, CEE는 분류 문제에 자주 사용된다.
참고. CEE, 교차 엔트로피 오차는 자연상수가 밑으로 있는 log를 사용하게 되는데 이때 예측값 y_hat이 0이라면 -inf의 값을 가져 계산이 진행되지 않기 때문에 아주 작은 값(delta)을 추가해 절대 0이 되지 않도록 만들어준다.
1.1.1. 미니 배치 학습
실제 학습하는 과정에서는 손실 함수를 계산할 때, 데이터를 하나하나 계산하고 갱신하는 과정을 거치지 않고 일정량의 크기로 데이터를 묶어 한번에 손실 함수를 계산하고 갱신한다.
이런 미니 배치 학습 방식을 자주 사용하기 때문에 손실 함수 수식이 아래처럼 일부 수정될 수 있다.
위 수식은 미니 배치 단위로 데이터를 학습에 사용할 때, 계산되는 손실값이다. 단순히 손실값의 평균을 구해주는 것을 볼 수 있다. (정규화)
1.1.2. 정확도가 아닌 왜 손실 함수를 사용할까?
정확도가 아닌 손실 함수를 사용해서 신경망을 학습하는 이유는 함수의 연속성 때문이다.
정확도는 데이터의 총 개수 중에서 맞춘 개수를 바탕으로 계산을 하게 된다. 즉, 100개 중 80개를 맞췄다면 정확도는 0.8, 80%가 되는 것인데 매개변수를 어떻게 바꿔야 이 수치가 올라갈지 알 수가 없다.
즉, 위 예시에서 정확도는 단위가 1만큼 오르고 낮아지는 수치이기 때문에 연속적이지 않고 미분값이 0인 부분이 많다. 이 때문에 학습에는 사용할 수 없다.
하지만 손실 함수는 연속적인 함수로 미분값을 알아낼 수 있다. 즉, 학습이 가능하다는 말이다.
손실 함수로부터 얻는 미분 값이 음수라면 양의 방향으로, 미분 값이 양수라면 음의 방향으로 매개변수를 이동시켜야 한다. 미분 값이 음수라는 것은 매개변수를 증가시켰을 때 손실 값이 작아진다는 의미이고, 미분 값이 양수라면 매개변수를 감소시킬 때 손실값이 작아진다는 의미이기 때문이다.
1.2. 수치 미분
위에서 손실 값을 바탕으로 매개변수마다 한순간의 변화량, 즉, 미분 값을 구한다고 했었다.
이때 사용하는 미분은 두 가지 방법으로 구할 수 있다.
바로 전방 차분과 중심 차분(중앙 차분)이다.
1.2.1. 전방 차분
전방 차분은 미세한 h(차이)에 얼마나 변화하는지 확인하는 미분법이다.
사실 전방 차분은 x부터 h만큼의 전방 값의 변화량을 구하기 때문에 실제 x에 대한 미분값과는 조금 다를 수 있다.
1.2.2. 중앙 차분 (중심 차분)
중앙 차분은 전방 차분과는 다르게 x를 중심으로 미분값을 구하게 된다. 이런 특징 때문에 전방 차분에서 발생하는 미소한 차이를 조금 더 줄일 수 있다.
전방 차분, 중앙 차분은 둘 다 미소한 변화에 대한 변화량을 직접 계산하기 때문에 사람이 정하는 미소한 변화에 대한 오차가 발생한다. 실제 미분에서 가장 많이 쓰이는 방법은 수식을 전개해서 미분값을 얻는 해석적 방법으로 가장 정확한 미분값을 얻을 수 있다.
1.2.3. 편미분
편미분은 어떤 함수가 2개 이상의 변수로 이루어져 있을 때 미분하는 방식이다.
편미분은 여러 변수 중에서 하나의 변수를 기준으로 미분하는 것이다.

1.3. 경사하강법
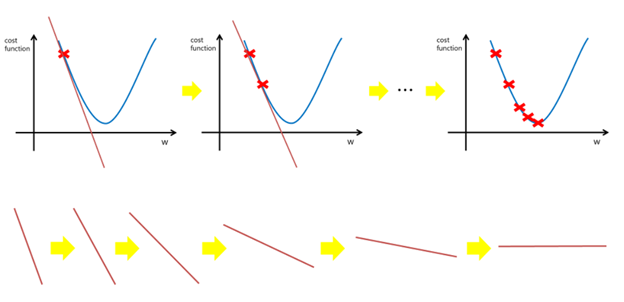
경사하강법은 Gradient Descent로 어떤 함수(손실)의 값이 가장 작아지는 방향으로 점차 나아가는 것을 말한다. 손실 함수에서는 초기 매개변수에 대한 기울기를 구해 매개변수를 조금 갱신하고 또 갱신하면서 손실 함수를 최소로 만드는 과정을 경사하강법이라고 할 수 있겠다.
1.3.1. 학습률 (Learning Rate)
학습률은 사용자가 미리 정하는 하이퍼 파라미터(hyper parameter)이다. 학습률은 손실 값에서 얻은 해당 매개변수의 기울기에서 얼마만큼 갱신을 수행할 것인지 정하는 수치이다.
학습률을 조정하기에 따라 학습이 진행되지 않을 수도, 학습이 빠르게, 느리게 진행될 수도 있다.
1.4. 학습
이번에는 모델이 실제 학습하는 과정을 보자.
- 미니배치
- 훈련 데이터의 일부를 무작위로 가져온다.
- 기울기 산출
- 미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구한다.
- 기울기는 미니배치의 손실 함수 값을 줄이는 방향을 나타낼 것이다.
- 매개변수 갱신
- 가중치 매개변수를 기울기를 참고하여 아주 조금 갱신한다.
- 1~3단계를 반복한다.
위처럼 실제 모델이 학습하는 과정에서는 데이터를 미니배치로 무작위로 선정하기 때문에 확률적 경사 하강법(SGD, Stochastic Gradient Descent)이라고 부른다.
1.4.1. 정리
- 기계학습에서 사용하느 데이터셋은 훈련 데이터와 시험 데이터로 나눠 사용한다.
- 훈련 데이터로 학습한 모델의 범용 능력을 시험 데이터로 평가한다.
- 신경망 학습은 손실 함술르 지표로, 손실 함수의 값이 작아지는 방향으로 가중치 매개변수를 갱신한다.
- 가중치 매개변수를 갱신할 때는 가중치 매개변수의 기울기를 이용하고, 기울어진 방향으로 가중치의 값을 갱신하는 작업을 반복한다.
- 아주 작은 값을 주었을 때의 차분으로 미분하는 것을 수치 미분이라고 한다.
- 수치 미분을 이용해 가중치 매개변수의 기울기를 구할 수 있다.
- 수치 비분을 이용한 계산에는 시간이 걸리지만, 그 구현은 간단하다. 한편, 다음 장에서는 구현하는 (다소 복잡한) 오차역전파법은 기울기를 고속으로 구할 수 있다.
'ML & DL > 복습' 카테고리의 다른 글
| 밑바닥부터 시작하는 딥러닝 Chapter 7 (0) | 2023.01.24 |
|---|---|
| 밑바닥부터 시작하는 딥러닝 Chapter 6 (2) | 2023.01.23 |
| 밑바닥부터 시작하는 딥러닝 Chapter 5 (0) | 2023.01.22 |
| 밑바닥부터 시작하는 딥러닝 Chapter 3 (0) | 2023.01.21 |
| 밑바닥부터 시작하는 딥러닝 Chapter 2 (0) | 2023.01.21 |