PDP (Partial Dependence Plot)
PDP는 어떤 모델이 예측값을 내보내는데 관심 feature의 값이 변화할 때 그 예측값에 얼마나 영향을 주는지 알 수 있도록 하는 시각화 방법이다.
예를 들어, boston 데이터(다양한 feature들로 집값 예측)에서 rm(방 수)가 예측값에 어떻게 영향을 미치는지 알고 싶을 때 사용할 수 있다. rm을 변경하면서 예측하는 것이 가장 간단한 방법인데 다른 수치형 변수나 범주가 많은 범주형 변수에 대해서도 그 값들을 모두 변경해보면서 예측할 수 있다.
작동 원리
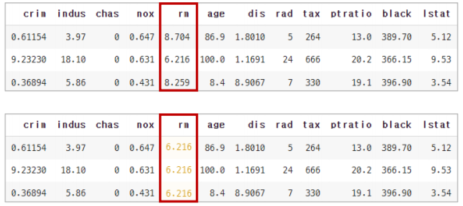
PDP가 작동할 때 함수 내부에서는 위와 같은 데이터에서 rm을 변경하면서 예측값을 뽑아낸다.
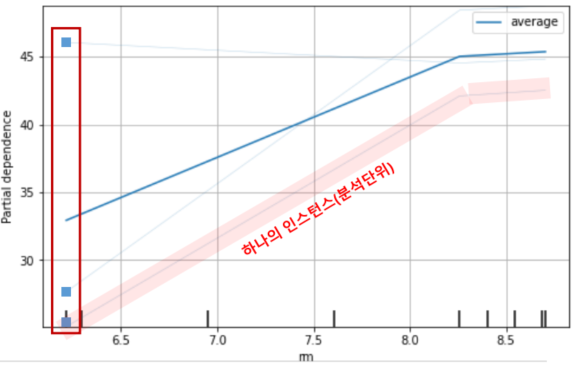
rm이 될 수 있는 값은 8.704, 6.216, 8.259이므로 모든 행 데이터에 대해서 rm변수에 이 세개의 값들을 하나씩 넣어보면서 예측값을 뽑아내고 그것의 평균을 구해 시각화를 하게 되면 위와 같은 그래프가 나오게 된다.
위의 그래프에서는 rm이 증가할수록 6.5 ~ 8.3 범위에서는 집값이 매우 크게 증가하고 그 이후로는 소폭으로 증가하는 것을 확인할 수 있다.
코드
메서드의 사용방법은 아래의 예시코드들과 같다.
kind의 옵션은 'average'가 default이며, 옵션의 종류는 average, individual, both가 있으며 average는 각 예측값의 평균값에 대한 선만, individual은 각 예측값들을 모두 시각화, both는 평균선과 예측값 선들 모두 시각화하라는 의미이다.
from sklearn.inspection import plot_partial_dependence
var = 'MonthlyIncome'
plot_partial_dependence(model, X=x_train, features=[var], kind='both')
plt.show()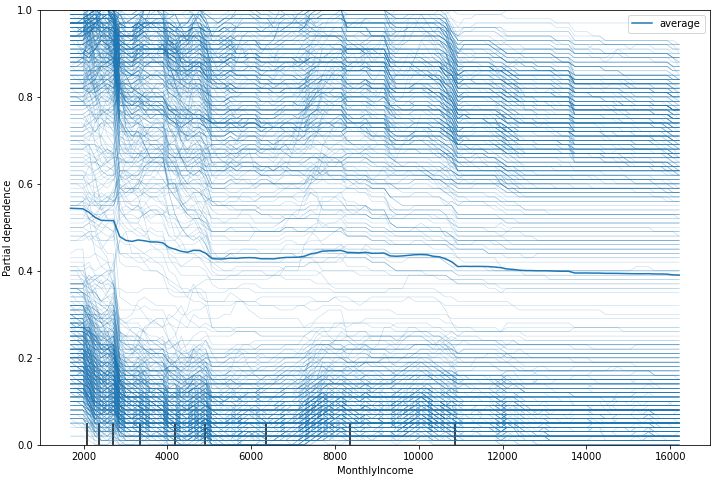
var = 'DistanceFromHome'
plot_partial_dependence(model, X=x_train, features=[var], kind='individual')
plt.show()
var = 'DistanceFromHome'
plot_partial_dependence(model, X=x_train, features=[var])
# default -> average
plt.show()
plot_partial_dependence(model, X=x_train, features=[('JobSatisfaction', 'DistanceFromHome')])
plt.show()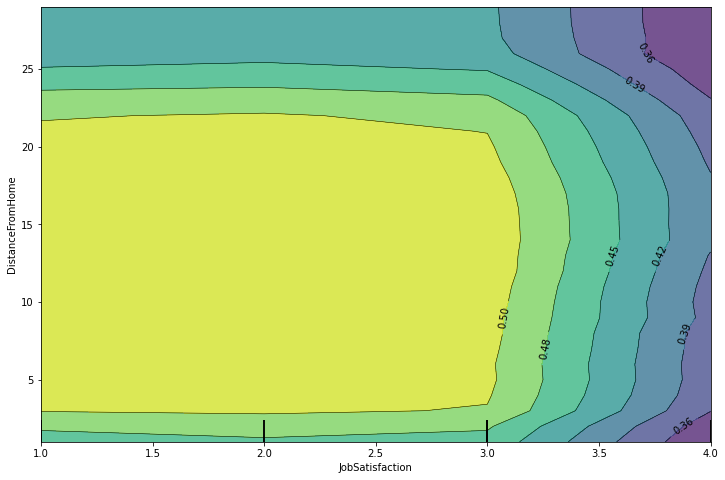
위 그래프와 같이 PDP를 사용할 때 변수를 소괄호로 묶어 2개로 변수 영향도를 확인할 수도 있다.
다만 2개 변수를 PDP로 확인할 때는 kind 옵션을 사용할 수 없다.
위의 그래프에서는 등고선이 있는 부분을 기점으로 사각형을 그려서 어느 부분에서 예측값이 다소 증가 또는 감소하는지 확인하는 것이 분석할 때 편하다.
+
XAI(설명가능한 AI)에서는 이러한 tool들도 중요하지만 설명할 수 있는 insight도 중요하다.
'ML & DL > XAI' 카테고리의 다른 글
| Shapley Values (shap) (0) | 2022.09.12 |
|---|---|
| 변수 중요도 (feat. Permutation Feature Importance) (1) | 2022.09.12 |