텍스트 마이닝
텍스트 마이닝은 NLP에서 필수적으로 필요한 과정이다. 텍스트 마이닝을 통해 NLP를 처리할 수 있는 기계학습/딥러닝 모델이 수월하게 입력을 받을 수 있다.
텍스트 마이닝이란 대규모 텍스트 자료를 분석하여 가치있는 새로운 정보를 찾아내는 과정을 말한다.
이 과정에서는 통계적, 기계학습/딥러닝 기법이 모두 사용된다.
텍스트 마이닝은 우리 주변에서 많이 사용되고 있다. 보통 뉴스나 sns같은 곳에서 업로드되는 문서를 사용하는 텍스트 마이닝을 찾아볼 수 있다. 이는 소셜 미디어 분석 서비스에 속하는데 사람들이 올리는 뉴스나 짧은 게시글을 통해 감성을 분석하거나 키워드에 대한 빈도나 같이 출현한 단어를 가지고 세부사항을 분석하거나 언급량으로 관심도를 파악한다.
문서 Clustering
문서를 분류하는 일은 NLP에서도 가장 중요하게 다뤄지는 일 중 하나이다. 문서들을 상황에 맞게 분류한다.
- 스팸 메일 분류
- 문서 카테고리 분류
- 감성 분석
- 의도 분석
위의 문서를 분류하는 예시들은 지도학습(Supervised Learning)으로 주어진 라벨을 학습하는 과정으로 분류할 수도 있지만 K-means Clusering이나 DBSCAN 기법을 활용하여 비지도학습으로 분류할 수도 있다.
K-Means Clustering
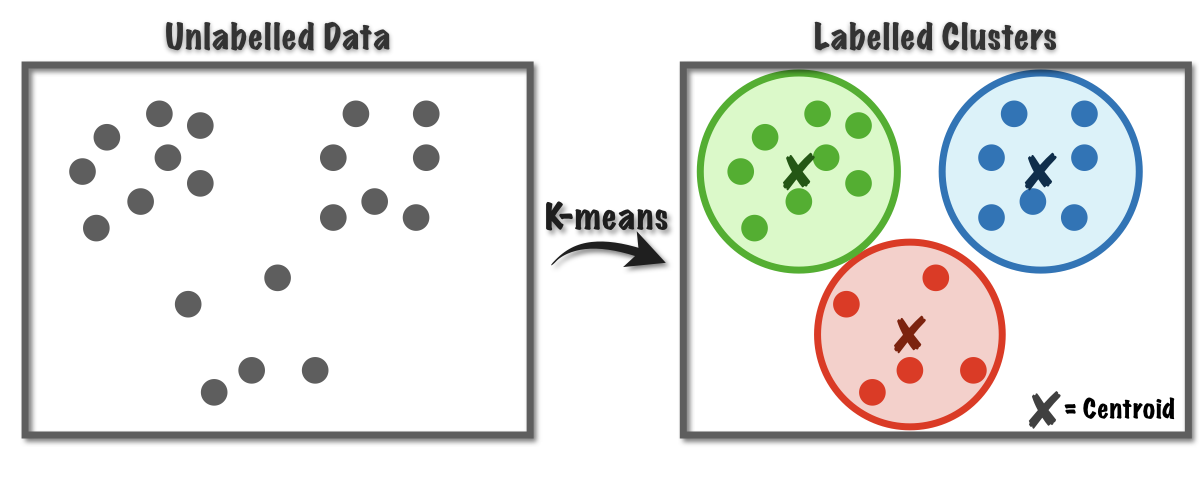
k means clustering은 기법의 이름처럼 k개의 중심점을 전체 점들의 평균을 사용해서 군집화하는 기법이다.
K-Means Clustering은 구글링을 통해 많은 자료를 얻을 수 있고 이미 한번 짚고 넘어간 기법이므로 작동순서만 다루고 넘어가겠다.
- 위 그림과 같은 데이터에 대한 점들이 있는 공간에서 무작위로 k개의 centroid를 지정한다.
- 데이터 점들은 k개의 centroid 중 자신과 가장 가까운 centroid에 속하게 된다.
- 가장 가까운 centroid를 선택한 데이터들끼리 평균을 구하여 그 지점으로 centroid를 이동시킨다.
- 모든 데이터 점들이 군집 과정에서 변하지 않을 때까지 2~3 과정을 반복한다.
DBSCAN
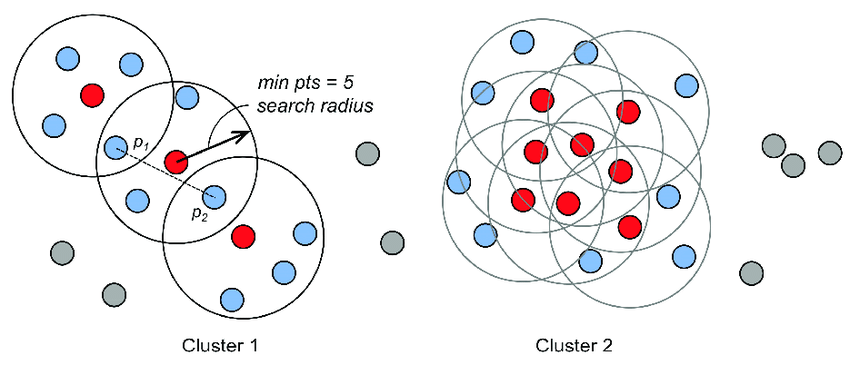
DBSCAN도 짧게 짚고만 넘어가겠다.
DBSCAN은 k-means clustering과 다르게 k라는 군집 개수를 지정하고 시작하지 않는다. 그러므로 k라는 hyper parameter를 모델 학습전에 정할 필요가 없다는 장점이 있다.
DBSCAN은 대신 epsilon, min_samples라는 hyperparameter를 가지는데 이 인수들의 뜻은 다음과 같다.
"중심점의 epsilon에 해당하는 반경 내부에 min_samples 개수 만큼의 데이터 점이 존재한다면 이는 현재 군집에 속한다."
- 처음에 데이터의 임의의 점을 core point로 지정한다.
- core point를 중심으로 eps만큼의 반경내에 min_samples 데이터 개수가 있는지 확인한다. 데이터 점의 개수가 만족한다면 반경 내에 속한 데이터 점들은 또 다른 core point가 된다. 만약 데이터 개수가 min_samples를 넘지 못한다면 현재 core point는 border point가 되며 군집화 진행을 멈춘다.
- 모든 점들이 군집화되거나 노이즈로 처리가 되도록 2번을 반복 수행한다.
DBSCAN은 노이즈가 있는 데이터에 대해서 노이즈(이상치)인지 판별할 수 있는 기능이 있고(k-means clustering은 없음) k를 지정할 필요가 없다. 하지만 데이터의 분포 밀도가 부분적으로 다를 때 밀도가 높은 부분에 대해서만 군집화가 이루어질 수 있다는 단점이 있다.

아래는 DBSCAN과 k-means clustering에 대한 차이이다.

DBSCAN은 데이터의 분포 모양에 영향 받지 않고 군집화를 진행할 수 있다. 하지만 k-means clustering은 반드시 수행전에 지정해놓은 k개 만큼의 군집을 만들어야 하고 군집화 방법때문에 복잡한 데이터 분포를 갖는 데이터에 대해서는 제대로 된 결과를 얻기 힘들 수도 있다.
문서 요약 (Text Summarization)
문서 요약은 문서의 내용을 요약하는 기술이다.
요약 기술은 두 가지 방법으로 나뉘는데 내용은 아래와 같다.
- 추출 요약 (Extractive Summarization)
- 추출 요약은 문서 내에서 문서를 대표하는 키워드나 핵심 문장을 선택해 문서를 요약하는 기술이다. 추출 요약은 통계 기반으로 작동하기 때문에 학습에 필요한 데이터가 필요없다.
- 추상 요약 (Abstractive Summarization)
- 추상 요약은 추출 요약처럼 문서 내에 존재하는 단어나 문장을 그대로 가져오는 것이 아니라 비슷하지만 새로운 단어나 새로운 표현의 문장을 가져와 요약하는 기술이다. 추출 요약과는 다르게 새로운 단어나 문장을 생성해야 하기 때문에 학습이 필요하다. (Supervised-Learning)
Text Rank
구글에 어떤 검색어를 입력했을 때 수많은 url이 사용자에게 표시된다. 구글은 이 중에서 어떤 것이 가장 상단에 위치되도록 설계했을까? 구글은 전통적인 방법으로 PageRank라는 기술로 검색어에 대한 URL을 최상단부터 제공했다.
물론 지금은 매우 복잡한 기술로 사용하겠지만 전통적으로는 PageRank가 사용되었다.
PageRank는 사이트들이 서로 reference하고 있다는 것에 착안해 가장 많이 참조되는 페이지에 높은 점수를 그렇지 못한 페이지에는 낮은 점수를 부여해 상단부터 하단까지 나열하도록 했다.
TextRank도 비슷한 원리로 수행된다. TextRank도 PageRank에서 처럼 서로 참조할 수 있는 지표가 필요하다. TextRank 기법에서는 co-occurrence graph를 생성하여 수행한다. co-occurrence는 어떤 문서에서 N-gram안에 같이 있는 단어들에 대한 관계 정보이다. 예를 들어 "I like you. I like football game. I enjoy playing guitar." 와 같은 문장이 있고 2-gram으로 co-occurrence를 측정한다고 하면 "I"와 "like"단어는 2번이나 같이 측정되었고 나머지 다른 단어들은 0번이나 1번 측정되었다.
즉, 어떤 단어에 대해서 같이 나올 수 있는 다른 단어를 유사도가 높다고 판단하는 것이다.
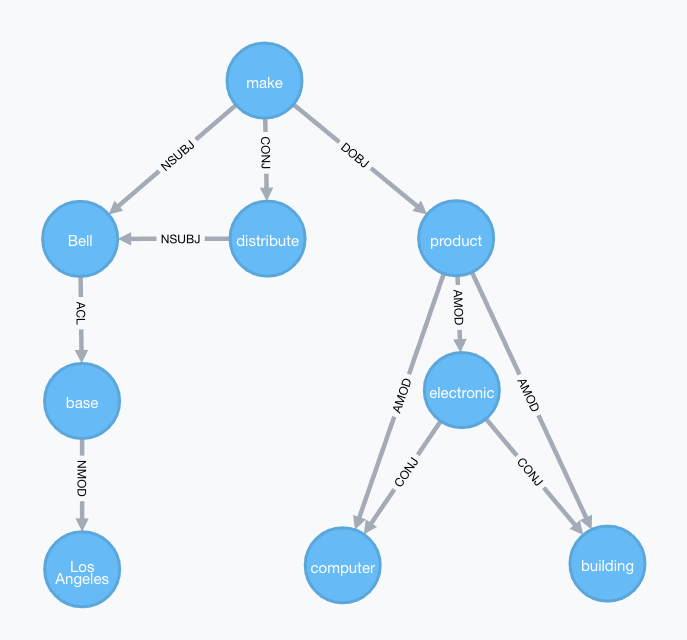
단어는 node에 위치하고 node간의 거리는 단어간의 유사도를 통해 결정된다. 어떤 단어 이후에 다음 단어가 얼마나 중요할 지에 대한 결과는 아래의 식으로 결정된다.
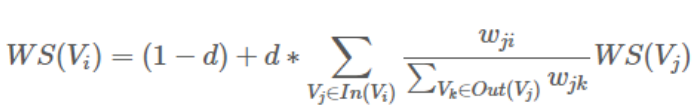
- node(vertex, 단어)의 초기 중요도를 1로 설정하고 현재 단어와 co-occurrence 관계가 있는 단어에 대해 edge를 생성한다.
- 새로 만들어진 node에 대해 위 식을 적용하고 수렴할 때 까지 반복한다.
(물론 위의 과정은 품사태깅이 필수적이며, 단어의 의미가 거의 없는 조사나 어미는 필터링한다.)
최종적으로 Text Rank를 통해 얻어진 node들의 중요도를 높은 것부터 차례대로 N개 만큼 선택한다. => 문서를 대표하는 단어 추출 성공
감성 분석 (Sentiment Analysis)
어떤 문서에 대해서 감성 분석을 하는 것은 지난 글에서도 언급된 적이 있다. 긍정 또는 부정과 같이 감성 분석을 진행한다. 오늘 다루는 감성 분석은 극성 뿐만 아니라 감성의 정도도 분석에 포함된다.
감성분석 세부
- Aspect-based sentiment analysis (polarity)
- 감성 분석의 정도 (수치)

Word Embedding (word2vec, word analogy)
이번 글에서 가장 중요한 word embedding이다.
지난 글에서도 문서를 수치화하는 과정, BOW(Bag of Words)에 대해서 다루긴 했지만 BOW는 너무 많은 차원을 가지고 각 단어마다의 정보를 한 벡터안에 가지고 있어 기계학습/딥러닝에 최적화된 vector라고 보기 어렵다. 이런 문제들을 해결하기 위해서 기존 BOW를 차원은 줄이고 각각의 단어마다 벡터화를 시키는 방법에 대해서 알아보자.
먼저 전통적인 word의 representation(BOW)은 벡터의 차원이 사전의 크기와 동일해야하며 해당되는 단어의 index에만 단어 등장 횟수나 가중치(TF or TFxIDF)가 들어가 순차적으로 단어를 넣을 수 없어 어떤 모델의 인풋으로 사용되기 어렵다.
그렇다면 단어마다 순차적으로 벡터화를 진행하면 되지 않는가?
그렇게 단순하게 시도된 방법이 one-hot encoding 방식이다. 단어의 사전 크기 만큼의 벡터에 해당 단어 index에만 1 나머지는 0을 가지는 벡터로 만드는 방식이다.
하지만 이는 1을 가지는 index를 제외하면 모두 0을 갖는 sparse한 벡터이므로 벡터 공간의 낭비가 심하고 다른 단어와의 유사도를 측정하기 어렵다는 단점이 있다.
이런 문제를 해결한 vector를 만들기 위해 관점을 똑똑한 학자들은 다르게 하기로 한다. 기존에 word 하나만을 중점적으로 보고 vector를 만들었던 것에서 word 주변의 문맥을 보고 vector를 추출하는 과정으로 변화시켰다.
당연히 우리가 뽑아낼 word vector는 주변의 문맥(context)과 영향을 주고 받기 때문에 vector에도 잘 반영할 수 있다고 볼 수 있다. 이런 방식은 분포 가설(Distributional hypothesis)에 기저하고 있다.
우리가 살펴볼 word2vec 기법에는 두 가지 방법이 존재한다. 방법은 아래와 같다.
- Continuous bag-of-word (CBOW)
- Skip-gram
Continuous Bag-Of-Word (CBOW)
주변 문맥을 가지고 중앙의 단어를 예측하는 과정에서 얻는 가중치로 vector를 구성하는 방법이다.
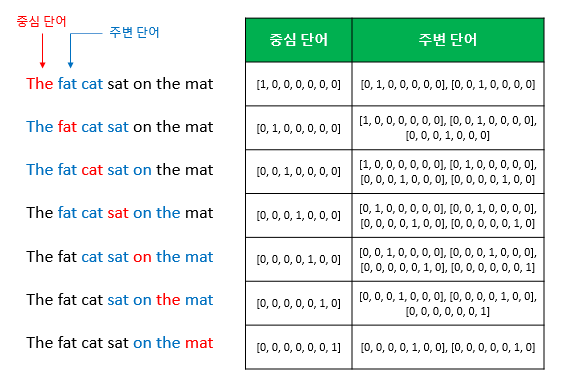
위 그림처럼 어떤 문장이 존재한다고 했을 때 CBOW는 sliding window처럼 단어들을 훑고 지나간다. 훑고 지나가면서 예측할 단어가 있는 부분을 제외하고 나머지 문맥에 해당하는 주변 단어들을 입력으로 넣고 1개의 은닉층을 지나 결과를 도출한다. 몇 개의 주변 단어들을 문맥(context)로 간주할 것인지는 학습전에 결정하고 결정에 따라서 학습 데이터셋이 위와 같이 생성된다.
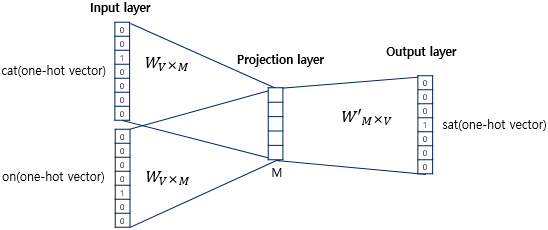
한 가지 더 미리 설정해야하는 것이 있는데 그것이 embedding 차원이다. 기존에 사전의 크기만큼의 vector 크기를 가져야했던 것에서 이제는 우리가 원하는 크기로 vector를 구성할 수 있다. 다만 대개 50~300 사이의 값에서 선택하며 너무 작으면 단어가 가지는 정보에서 손실이 있을 수 있고 반대로 너무 크면 연산량이 높아 BOW와 비슷한 문제가 발생할 수 있다.
위의 Neural Network에서 W, W' 가중치는 output layer에서 문맥에 대한 결과 단어를 예측하도록 학습이 된다. 모든 학습이 이루어지면 W 가중치를 각 word의 embedding vector로 사용한다. (위 그림 예시에서는 projection layer vector의 크기가 5가 되도록 설정했는데 이는 W의 크기가 7x5가 된다는 것을 알 수 있고 학습이 완료되면 이 7개의 단어들이 각각 5크기의 embedding vector를 가지게 되는 것이다.)
참고.
당연히 기존의 단어 벡터들은 one-hot vector이다. projection layer에서의 값은 각각의 input과 가중치 W의 계산결과의 평균이 된다. output layer는 softmax에 의해 각자 확률로 값이 도출되며 가장 큰 확률값이 예측값이 된다. loss로는 cross entropy가 사용된다.
Skip-gram
Skip-gram 방법은 CBOW와는 반대로 한 단어를 가지고 문맥을 예측하는 모델을 학습하는 과정에서 embedding vector를 얻는다.
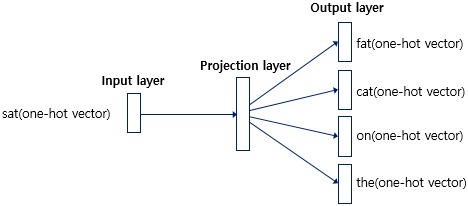
skip gram 방법은 한 단어로 문맥을 예측하는 과정이기 때문에 비슷한 단어에서 같은 문맥을 예측하는 상황도 분명 있을 것이다. 이런 과정은 합리적으로 생각했을 때 당연한 것이다. 비슷한 단어에서는 비슷한 문맥을 가지는 문장이 생성될 수 있기 때문이다. 예를 들어, "우리는 아침식사로 오렌지 주스와 크로와상을 주문했다."라는 문장이 있을 때 input 단어가 오렌지라고 해보자. 이때 우리는 "오렌지"라는 단어 대신 오렌지와 비슷한 과일류인 "사과", "포도", "복숭아" 등등이 input단어로 들어가도 비슷한 문맥으로 문장이 형성될 수 있다는 것을 알고 있다. 이 때문에 skip-gram으로 생성된 embedding vector는 비슷한 부류의 단어일때는 유사도가 상당히 높게 형성된다.
Word2Vec 결과

결과적으로 우리는 word2vec 기법을 통해 word들을 효과적으로 그 의미들을 잘 담으면서 작은 차원의 vector로 만들 수 있다.
Word Analogy
앞서 word2vec에 의해 word를 각각의 vector로 만들었다면 이 벡터들의 유사도를 구할 수 있게 된다. (코사인 유사도)
정말 신기하게도 단어 벡터들의 유사도를 구해보면 비슷한 부류의 단어 벡터들은 비슷한 벡터를 가진다.
그리고 embedding vector의 내부 값을 관찰해보면 비슷한 부류의 단어 벡터들은 구성 값들도 비슷하다.
이를 분산 재표현 (Distributed Representation)이라고 한다. 벡터 내부의 하나하나의 값들이 표현할 수 있는 단어는 정말 많다. 각각의 벡터 내부값들이 표현 관점에서 의미를 가지는 것이다.
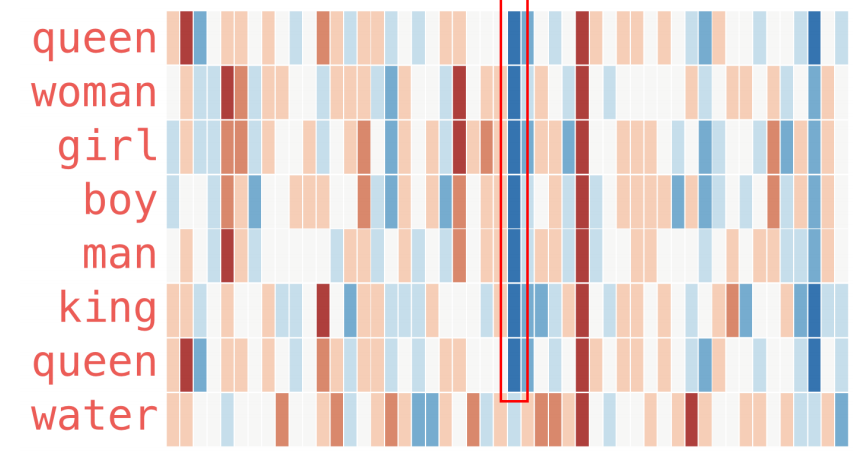
위와 같은 벡터들의 모습에서 "water"는 사람이 아니고 나머지는 사람과 관련되 단어이다. 분명 사람과 관련되어 있기 때문에 비슷한 값을 찾을 수 있는데 그 값이 "water"에서는 확연히 다른 모습인 것을 찾을 수 있다.
추가
이렇게 embedding vector로 변환된 word들은 각각이 지니는 벡터들의 유사도를 통해 비슷한 단어, 문장들을 추천할 수도 있고 학습과정에서 데이터 증강(Data Augmentation) 목적으로 사용될 수도 있다.
기법들도 또한 자연어뿐만이 아니라 airbnb나 노래어플에서 추천 기법, paraphrasing으로도 사용될 수 있다.
Reference
https://ebbnflow.tistory.com/292
[NLP] 키워드와 핵심 문장 추출(TextRank)
Summarization NLP Task의 한 종류로 문서 집합에서 핵심되는 문장을 추출하거나 요약하는 분야를 말한다. Summarization의 접근법은 크게 두 가지가 있다. 1. Extractive Approaches ➡️ Unsupervised Learning..
ebbnflow.tistory.com
https://velog.io/@cha-suyeon/%EC%9B%8C%EB%93%9C%ED%88%AC%EB%B2%A1%ED%84%B0Word2Vec
워드투벡터(Word2Vec) - CBOW, Skip-gram
Sparse RepresentationDistributed representationCBOW(Continuous Bag of Words)Skip-gram원-핫 벡터는 단어 간 유사도를 계산할 수 없다는 단점이 있습니다. 단어 간 유사도를 반영할 수 있도록 단어의 의미를
velog.io
'ML & DL > NLP' 카테고리의 다른 글
| NLP(자연어 처리) 입문 6 - RNN, LSTM (0) | 2022.10.07 |
|---|---|
| NLP(자연어 처리) 입문 5 - CNN 기반 텍스트 분류 (0) | 2022.10.05 |
| NLP(자연어 처리) 입문 3 - 기계학습 (1) | 2022.10.03 |
| NLP(자연어 처리) 입문 2 - 패턴 매칭 (0) | 2022.10.02 |
| NLP(자연어 처리) 입문 1 - 품사 태깅, 형태소 분석 (0) | 2022.10.02 |