RNN
RNN은 Recurrent Neural Network의 약자로 순환 신경망이라고 부르는 sequence model이다.
sequence형태의 input을 받아 sequence 형태의 output을 내뱉는다.
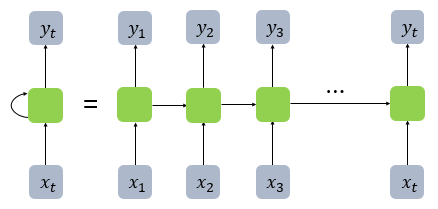
위의 그림은 RNN의 구조이다. 왼쪽 그림은 RNN의 진짜 구조이고 오른쪽은 시간에 따라 unfold한 모습이다.
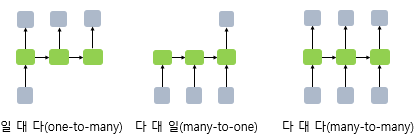
RNN은 위 그림과 같이 task에 따라 one-to-many, many-to-one, many-to-many 방식으로 결과값을 조절할 수 있다.
RNN의 작동방식

RNN은 입력으로 들어오는 x와 직전 시점(t-1)의 h(hidden state)의 가중치 합에 의해서 현재 시점의 hidden state를 도출하고 이를 다시 선형, 비선형 계산을 통해 결과값을 도출해낼 수 있다.
tanh
위의 수식에서 f에 해당하는 활성화함수는 어떤 task냐에 따라 달라질 수 있으며, tanh(하이퍼볼릭 탄젠트 함수)의 경우 아래와 같은 그래프를 보이는데

sigmoid보다 두 배 큰 범위를 가져 sigmoid함수보다 gradient vanishing될 확률을 다소 줄일 수 있으며, 출력값이 절대값 1미만의 값으로 만들 수 있어 값의 범위를 제한적으로 만드는 기능이 있다.
다만, sigmoid와 비슷한 이유로 input값이 너무 작거나 클 때 기울기가 0에 가까워지고 이를 여러번 거치는 backpropogation이 진행되면 gradient vanishing 문제가 발생할 수 있다.

결과적으로 RNN은 어떤 한순간의 시점에서 위와 같은 연산이 진행되어 hidden state를 도출하게 된다.
- RNN은 유연한 크기의 sequence를 input으로 받을 수 있는 sequence model
- tanh를 사용 → gradient vanishing 문제 발생 가능
- 긴 sequence가 input으로 들어올 때 hidden state 정보에서 초기부분에 대한 정보가 많이 소실되어 성능이 저조할 수 있다.
- hidden state가 keyword! 시간이 흐르면서 hidden state안에 sequence의 정보들이 담기게 된다.
LSTM (Long Short-Term Memory)
LSTM은 RNN의 gradient vanishing/exploding 문제를 해결하고 긴 sequence가 input으로 들어오더라도 input의 초기부분 단어에 대해 정보를 잘 전달할 수 있다. (정보의 장거리 전달 가능)

LSTM은 위와 같은 구조를 가진다. RNN과 구조 생김새는 어느정도 비슷하나 내부적인 연산에서 다른점을 보인다.
LSTM은 이전시점의 hidden state와 현재 시점의 input을 받아 현재 시점의 hidden state를 도출하는데 이 부분은 RNN과 동일하다. LSTM은 여기서 cell state라는 개념이 추가되어 cell들이 가지고 있는 context 정보를 중, 장기적으로 유지하려고 한다.
LSTM은 input gate, forget gate가 추가되며 자세한 내용은 다음과 같다.
Input Gate

입력 게이트에서는 이전 시점의 hidden state와 현재 시점 input인 x를 받아 선형연산 후 하나는 sigmoid, 나머지 하나는 tanh연산을 진행하여 곱하게 된다.
이 때 sigmoid는 LSTM의 모든 연산에서 같은 기능을 하게 되는데, 그 기능은 gate의 개폐를 맡는다고 볼 수 있다.
선형연산 + tanh의 결과값이 얼마나 cell state에 더해지게 할지를 sigmoid 결과가 결정하는 것이다.
sigmoid는 기본적으로 0~1사이의 값을 갖기 때문에 sigmoid 결과와 곱해진다는 의미는 전체에서 얼마만큼의 결과양을 다음으로 전달하겠냐는 의미이다.

결과적으로 위와 같은 연산을 진행하고 i와 g는 곱셈에 의해 cell state에 더해져 현재 시점의 cell state를 만들게 된다.
Forget Gate
forget gate는 이전 시점의 cell state를 얼마나 유지할지에 대한 개폐과정이다.
이 과정 역시 먼저 이전 시점의 hiddent state와 현재 시점의 input인 x를 가중치합 + sigmoid를 하여 0~1의 값으로 도출한다.

sigmoid까지 거친 결과값은 이전 시점의 cell state와 곱해져 기존의 cell state의 부분적인 크기를 가지게 된다.
이전 cell state는 이전 input들의 문맥적인 의미를 가지고 있는데 현재 input과 hidden state를 통해 그 문맥의 의미 크기를 일부 조정하는 과정이다.
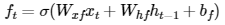
forget gate의 수식은 위와 같다.
Cell State
Cell state는 이전의 문맥정보를 담고 있다.
만약 forget gate에서 0이 곱해졌다면 현재 시점의 cell state는 온전히 현재 시점의 input gate 값이 될 것이다.
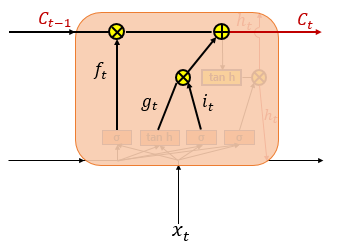
cell state 수식은 아래와 같다. (위에서 정리한 forget gate와 input gate가 사용된다.)
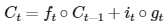
Hidden State or Output Gate
마지막으로 hidden state이다. hidden state는 LSTM cell에서 현재 시점의 최종적인 output 값이라고 할 수 있다. (cell state는 문맥적인 정보를 전달할 뿐 output으로 도출되지는 않는다.)
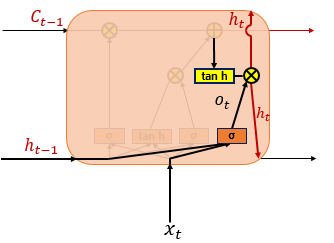
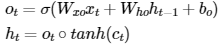
현재 시점의 hidden state를 계산할 때는 다른 gate와 동일하게 output gate에 의해 0~1의 개폐를 가지고 있다. 이전에 설명한 cell state 결과값에 tanh 활성화함수를 거쳐 output gate값(0~1)을 곱하면 현재 시점의 hidden state를 구할 수 있다.
LSTM 코드
class RNN_Text(nn.Module):
def __init__(self, embed_num, class_num):
# super()로 Base Class의 __init__() 호출 (nn.Module 클래스 생성자 호출)
# super(파생클래스, self).__init__() 파이썬 2.x 문법
# super().__init__() 파이썬 3.x 문법 둘다 사용 가능
super(RNN_Text, self).__init__()
V = embed_num # 단어 사전의 크기
C = class_num # 분류하고자 하는 클래스 개수
H = 256 # 히든 사이즈
D = 200 # 단어벡터 차원 100 (B, 30, 21893) -> (B, 30, D)
self.embed = nn.Embedding(V, D)
# LSTM Layer, bidirectional이므로 출력되는 벡터의 크기는 H * 2
self.rnn = nn.LSTM(D, H, bidirectional = True)
# Linear Layer : (512, 2)
self.out = nn.Linear(H*2, C)
def forward(self, x):
print(x.size())
x = self.embed(x) # (N, W, D) 문장 x의 단어 벡터값 가져옴
print(x.size()) # (W, N, D)
# LSTM 모듈 실행
# LSTM 입력데이터
# input x : torch.Size([30, 100, 100]) [시퀀스 길이, 배치 사이즈, Dimension]
x,(_,__) = self.rnn( x, ( self.h, self.c ) )
# output x : torch.Size([30, 100, 512]) [시퀀스 길이, 배치 사이즈, 256 * 2]
# 최종 Hidden Layer로 Linear 모듈 실행
logit = self.out(x[-1]) # 마지막 단어 위치에 해당하는 hidden state를 가져와서 self.out에 넣음
# 최종 예측 벡터 크기: [배치 사이즈, C], C: 클래스 개수
return logit # logit : torch.Size([100, 2])
def inithidden(self, b):
#self.h = Variable(torch.randn(2, b, 256))
#self.c = Variable(torch.randn(2, b, 256))
self.h = torch.randn(2, b, 256) # [2, batch_size, 256]
self.c = torch.randn(2, b, 256) # [2, batch_size, 256]다음은 코드 진행과정이다.
코드를 따라가면서 input이 embedding vector로 바뀌고 LSTM에 들어가 연산되는 과정이 이해가 잘 가지 않았는데 어찌저찌 잘 이해했다!
까먹으면 다시 봐야하므로 진행과정을 아래에 써보자.
- 처음 input인 x의 shape = (sequence내 단어 개수(Field에서 제한한 fix_length), Batch Size)
- embedding layer에 의해 x가 내부적으로 one-hot encoding된 뒤 word embedding 처리되어 shape 변경됨 → (sequence내 단어 개수(Field에서 제한한 fix_length), Batch Size, 임베딩 차원 크기)
- LSTM의 input으로 들어감.
- input gate, forget gate, output gate등의 가중치 W와 matmul 연산되어 200→256차원(hidden size)의 크기가 도출.
- 4번의 값과 W*h(hidden state)를 합하고 bias가 더해져 각 gate 및 input에 들어간다.
- 이때 hidden state와 cell state는 bidirectional LSTM이기 때문에 (2, batch size, 256) shape를 가진다. 원래는 (1, batch size, 256)임.
- 양방향 LSTM이기 때문에 현시점의 hidden state(256차원)가 두 개 concat 되어 512차원이 된 뒤 linear(512, 2)를 만나 최종 결과값이 나온다.
Reference
1) 순환 신경망(Recurrent Neural Network, RNN)
RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델입니다. 번역기를 생각해보면 입력은 번역하고자 하는 ...
wikidocs.net
2) 장단기 메모리(Long Short-Term Memory, LSTM)
바닐라 아이스크림이 가장 기본적인 맛을 가진 아이스크림인 것처럼, 앞서 배운 RNN을 가장 단순한 형태의 RNN이라고 하여 바닐라 RNN(Vanilla RNN)이라고 합니다 ...
wikidocs.net
https://pytorch.org/docs/stable/_modules/torch/nn/modules/rnn.html#LSTM
torch.nn.modules.rnn — PyTorch 1.12 documentation
Shortcuts
pytorch.org
https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
LSTM — PyTorch 1.12 documentation
Shortcuts
pytorch.org
https://torchtext.readthedocs.io/en/latest/data.html#fields
torchtext.data — torchtext 0.4.0 documentation
torchtext.data The data module provides the following: Ability to define a preprocessing pipeline Batching, padding, and numericalizing (including building a vocabulary object) Wrapper for dataset splits (train, validation, test) Loader a custom NLP datase
torchtext.readthedocs.io
https://github.com/piEsposito/pytorch-lstm-by-hand/blob/master/LSTM.ipynb
GitHub - piEsposito/pytorch-lstm-by-hand: A small and simple tutorial on how to craft a LSTM nn.Module by hand on PyTorch.
A small and simple tutorial on how to craft a LSTM nn.Module by hand on PyTorch. - GitHub - piEsposito/pytorch-lstm-by-hand: A small and simple tutorial on how to craft a LSTM nn.Module by hand on ...
github.com
'ML & DL > NLP' 카테고리의 다른 글
| NLP(자연어 처리) 입문 8 - Transformer (0) | 2022.10.08 |
|---|---|
| NLP(자연어 처리) 입문 7 - Seq2Seq, Attention (0) | 2022.10.08 |
| NLP(자연어 처리) 입문 5 - CNN 기반 텍스트 분류 (0) | 2022.10.05 |
| NLP(자연어 처리) 입문 4 - 텍스트 마이닝 (word2vec) (1) | 2022.10.04 |
| NLP(자연어 처리) 입문 3 - 기계학습 (1) | 2022.10.03 |