
1. Seq2Seq (시퀀스 투 시퀀스)
seq2seq 기법은 transformer가 2017년에 제안되기 전까지 딥러닝 기계번역에서 state-of-the-art였던 기법이다.
이전까지의 기계번역 기법들보다 훨씬 큰 성능을 나타냈으며 Context Vector라는 새로운 개념의 도입으로 이 후 제안된 유명 기법 논문들에도 영향을 많이 끼치게 된다.

seq2seq는 RNN 또는 LSTM을 사용하여 구현할 수 있다. 여기서는 LSTM 기반의 seq2seq라고 가정하자.
seq2seq의 구조는 위 그림과 같다.
인코더에서 LSTM 한 개, 디코더에서 LSTM 한 개를 사용해 기계번역과 같은 task를 처리한다.
이 때 인코더에서는 순차적으로 sequence를 받아 내부적으로 hidden state를 누적하여 최종적으로 디코더에 context vector를 만들어 보내게 된다.
즉, Context Vector에는 앞서 인코더에서 들어왔던 sequence의 내용들이 모두 들어있는 것이다.
아래는 실제 입력부터 출력되는 과정을 순서대로 나열한 것이다.
- 인코더에 sequence의 단어들을 순차적으로 넣는데, 넣기 전에 embedding layer를 거쳐 word embedding화한다.
- 순차적으로 단어들을 넣으면 이전 시점의 hidden state와 현재 시점의 단어 입력을 받아 새로운 hidden state를 만든다.
- 모든 sequence 내 단어들에 대해서 2번을 진행하면 마지막으로 출력되는 output hidden state는 Context Vector가 된다.
- 디코더에서는 Context Vector와 <sos> (start of sequence, 시작을 알리는 special token)을 받아 번역을 시작한다.
- 이후 이전 시점의 결과와 이전 시점의 hidden state를 받아 현재 시점의 번역 결과를 내뱉는다.
- 디코더에서 각 시점에서 내뱉는 출력 벡터는 완전연결층과 softmax를 거쳐 token → index → word가 된다.
1.0.1. seq2seq의 단점
seq2seq는 context vector를 만들어 decoder에 전달함으로써 모든 sequence에 대한 정보를 디코더에 넘길 수 있었지만 초기 부분에 들어온 단어의 경우에는 그 문맥 의미가 희석되어 디코더에서 감지하기 어렵다. 또한 context vector라는 고정된 크기 벡터에 모든 sequence 정보를 담는 과정에서 정보 손실이 발생한다.
더불어 순차적으로 입력이 들어가고 나가는 과정때문에 back propogation을 진행할 때 기울기 소실 문제가 발생할 수 있다. (Gradient Vanishing)
→ 이후 이런 문제들을 해결하기 위해 인코더의 단어 정보들을 그때 그때 사용하는 아이디어의 Attention 기법이 출현하게 된다.
2. Attention
Attention은 기법의 이름에서 알 수 있듯이 디코더에서 어떤 결과를 출력하기 전에 인코더에서 입력으로 받은 단어들 중 어떤 것에 주의를 기울여(attention) 참고하는 기법이다.
위 그림은 디코더의 세번째 Cell(LSTM)이 번역되는 세번째 단어를 예측하기 위해서 인코더의 output값들을 참고하는 과정이다.
이전 그림에서의 3 번째 LSTM Cell을 보면 출력값을 인코더쪽으로 보내 인코더의 출력값들과 유사도를 측정한다. 그리고 디코더의 현재 시점 결과값과 가장 유사하다고 판단되는 부분을 softmax에 의해 추출하여 참고하고 최종결과를 내뱉는다.
이것이 Attention 기법에서 말하는 Attention Score를 인코더에서 계산하고 디코더에서 참고하는 방법이다.
이후 Attention 기법을 활용하여 제안된 Transformer 기법에서도 다루겠지만 Query와 Key를 사용해 유사도를 구해 Attention Score를 구할 수 있다.
일단 Attention 기법에서는 Query, Key, Value라는 개념은 아직 도입하지 않고 비슷한 느낌으로 사용되는 것에 주목하자.
다시 정리하자면 Attention 기법에서는 현재 시점 디코더의 결과값(hidden state)과 인코더의 모든 결과값(hidden state)를 서로 비교하여 유사도를 판단하고 이를 softmax에 넣어 추출된 결과를 가중합을 하여 하나의 벡터로 만들어준다.
내적(dot product)는 유사도 계산과 동일하기 때문에 디코더의 hidden state와 인코더의 hidden state를 내적하는 과정은 유사도를 측정하는 것과 같다.
각 인코더의 hidden state들과 유사도를 계산했다면 softmax를 통해 각각을 확률값으로 만들어준다.
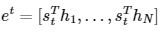

이 후 각각의 확률값들을 인코더의 해당 hidden state와 곱하고 그 결과들을 더해 가중합을 취한다.
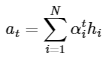
가중합을 취하면 하나의 벡터가 나오게 되는데 이는 인코더 및 디코더의 hidden state 벡터 크기와 동일하다.
이 벡터를 디코더 현재시점의 hidden state에 concat하여 새로운 벡터를 만든다.

최종적으로 이전에 만든 벡터를 선형 연산과 비선형 연산을 한번씩 거쳐 마지막 결과 벡터를 만든다.
이 벡터를 선형연산과 함께 softmax를 취해 확률값으로 만들어 다음 번역된 단어를 찾으면 완료이다.


2.0.1. Attention 기법 두 가지
위에서 정리한 Attention 기법은Luong Attention 기법을 기준으로 정리한 것이다. Luong Attention 이외에도 다양한 Attention 기법이 있지만 대표적으로 Bahnadau Attention이 있다.
Bahnadau Attention은 위에서 설명한 Luong Attention과는 다르게 디코더에서 이전 시점의 출력값(hidden state)를 attention에 사용하여 현재 시점의 출력값을 계산할 때 사용한다.
결과적으로 아래 그림처럼 context vector(인코더에서 뽑아낸 Attention 결과)가 추가되어 현재시점의 디코더 hidden state를 구하게 된다.

이 후 과정은 일반 Attention(Luong Attention)과 동일하다.
2.0.2. Reference
1) 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 ...
wikidocs.net
2) 바다나우 어텐션(Bahdanau Attention)
앞서 어텐션 메커니즘의 목적과 어텐션 메커니즘의 일종인 닷 프로덕트 어텐션(루옹 어텐션)의 전체적인 개요를 살펴보고, 마지막에 표를 통해 그 외에도 다양한 어텐션 메커니즘이 ...
wikidocs.net
'ML & DL > NLP' 카테고리의 다른 글
| BERT와 KoBERT(Word-Piece Embedding, 코드리뷰) (0) | 2022.10.19 |
|---|---|
| NLP(자연어 처리) 입문 8 - Transformer (0) | 2022.10.08 |
| NLP(자연어 처리) 입문 6 - RNN, LSTM (0) | 2022.10.07 |
| NLP(자연어 처리) 입문 5 - CNN 기반 텍스트 분류 (1) | 2022.10.05 |
| NLP(자연어 처리) 입문 4 - 텍스트 마이닝 (word2vec) (1) | 2022.10.04 |