
1. Transformer
Transformer는 RNN의 단점을 개선한 Attention 기법을 활용하여 인코더와 디코더 구조를 갖추고 있으며 Attention 기법의 장점 때문에 sequence를 순차적으로 계산할 필요가 없어 계산속도가 비교적 빠르다.
Transformer는 이 후 제안되는 현재 state-of-the-art 기법들인 GPT나 BERT에 큰 영향을 주었다.
Transformer는 앞서 언급했듯이 인코더와 디코더로 이루어져 있는데 구조는 아래와 같다.

1.1. Transformer의 Encoder
Transformer의 인코더는 multi-head Attention 기법과 feed forward층으로 이루어져 있으며 residual 층도 가진다.
1.1.1. Positional Encoding
Transformer에서 새롭게 등장하는 positional encoding은 입력으로 들어오는 단어가 sequence의 어느 위치에 있는지를 판단할 수 있도록 하는 척도로 network에 위치정보를 주고자 고안된 기법이다.
실제 우리는 문장을 읽을 때 단어와 위치에 대한 정보를 같이 파악한다. 기계도 이것을 인지하도록 만들기 위해 고안된 것!
예를 들어, 사람은 "나는 철수와 밥을 먹었다" 라는 문장이 "나는 밥을 철수와 먹었다" 라는 문장과 동일하다는 것을 알고 또 "나는 밥과 철수를 먹었다" 라는 문장과는 다르다는 것을 인지할 수 있다. 하지만 위치정보가 없는 sequence 정보를 기계가 봤을 때는 이들은 모두 같은 의미로 해석할 수 있기 때문에 위치정보가 필요한 것이다.
(Attention이 아닌 다른 RNN, LSTM, seq2seq에서는 인코더에서도 순차적으로 문장이 들어가기 때문에 이런 문제가 발생하지는 않는 것을 보인다. Attention은 input을 한번에 입력하기 때문에 위치정보가 필요!)
결과적으로 토큰이 들어있는 input을 word embedding을 통해 embedding vector로 변경하고 positional encoding을 통해 벡터에 위치정보를 추가하는 방식이다.
1.1.2. Multi-Head Attention
Transformer에는 세가지의 attention이 들어있다. 그 중 Encoder에서의 Attention은 Multi-Head Self Attention으로 여러 개의 head가 존재하는 self Attention이다.
먼저 모든 Attention 기법에 통용되는 개념을 짚고 넘어가자.
Attention 기법에는 세가지 개념을 도입해서 사용한다. 이는 아래와 같다.
- Query(Q)
- Key(K)
- Value(V)
만약 우리가 위 그림의 오른쪽에서 "it"이라는 단어를 결과값으로 추출해야하는 상황이라고 해보자. "it"이 지칭하는 것이 무엇인지 문맥에서 찾을 수 있어야 한다. 이 때 Attention 기법을 사용해 모든 sequence를 "it"과의 유사도를 구해 Attention할 단어들을 고르는 것이다.

각 Q, K, V의 값은 각 단어에 해당되는 hidden state마다 존재한다. 인코더에서는 hidden state가 입력값이 되어 Q, K, V가 구해지는 것이다.
위 그림에서는 student라는 단어가 들어오게 되는데 이는 사실 트랜스포머의 encoder에서는 hidden state에 해당할 것이고 1x4 차원에서 4는 embedding 차원을 의미하므로 논문에 따르면 512(d_model)이 되어야 한다.
이후 각자의 Q를 가지고 나머지 단어들의 Key와 연산하여(dot product → 유사도 계산) 결과값을 추출한다. Query와 Key가 내적을 한다는 의미는 유사도를 계산한다는 의미와 동일하며 그 값은 클수록 유사도가 크기 때문에 softmax 결과에서도 가장 큰 확률을 얻을 수 있다.
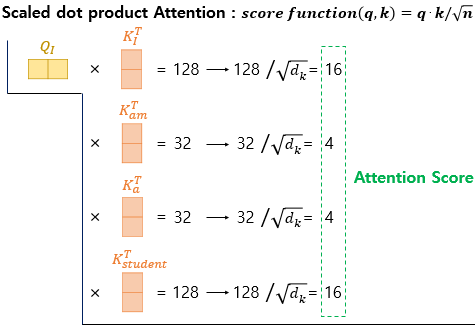
위 수식과 같이 Q와 K의 연산을 통해 Attention Score를 계산하고 softmax를 취해 마지막으로 V와 dot product를 진행한다.
그 진행과정은 아래와 같다.
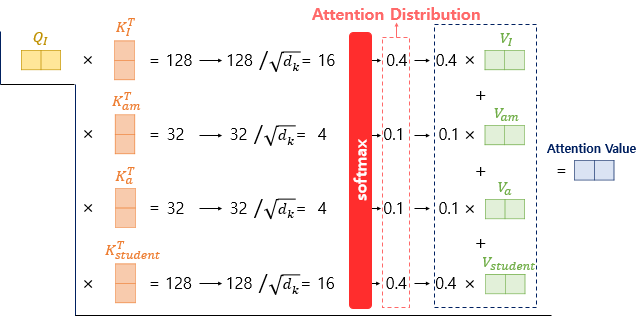
여기서 실제 소스코드와 헷갈리는 점이 있었는데 바로 차원이다.
논문에서는 d_model이라는 embedding 차원, 즉, encoder와 decoder의 입력 차원을 512로 설정했고 head는 8로 두었는데 결과적으로 Q, K, V의 차원이 각각 64차원을 갖는다는 의미이다.
음... 처음 input부터 차원만을 가지고 진행해보면 아래와 같다.
- input → (Batch size, max_length(sequence의 최대 길이))
- word embedding + positional embedding → (Batch size, max_length, 512) => 한 단어는 (1, 1, 512)
- n_head만큼 잘라서 Q, K, V만들기 (하나의 단어를 부분적으로 n_head만큼 잘라 따로 Attention 진행) → (Batch size, max_length, 512 / n_head = 64)
결과를 보면 아래와 같아진다.

결과적으로 아래와 같은 연산을 모두 진행하게 된다.
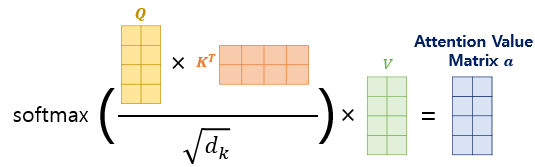

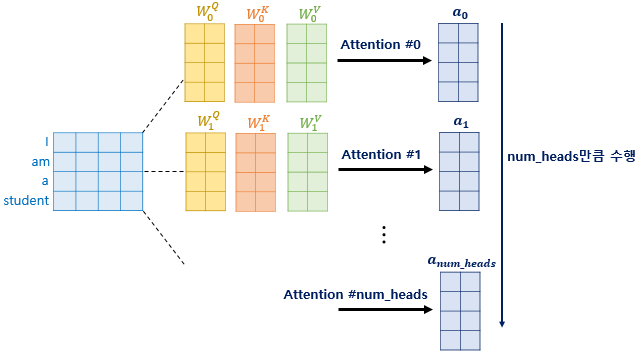
수행된 attention matrix들은 다시 concat하여 원래의 hidden state matrix 크기와 동일하게 복구된다.
1.1.3. Padding Mask
사실 우리는 input sequence를 encoder에 넣어주기 전에 여러 전처리를 하는데 그것 중 하나는 padding이다. input으로 들어가는 sequence의 길이는 일정해야하기 때문에 이를 20이나 30과 같은 일정 수치로 고정시켜주게 되고 sequence길이가 이 보다 짧은 경우는 나머지를 padding해주고 긴 경우에는 잘라준다.
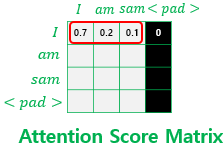
padding을 한 경우에는 token이 <PAD>라는 의미없는 값이 들어가게 되는데 encoder에서 Attention을 진행할 때 단어들이 이 <PAD> token에 attention 하지 못하게 해야한다.
그렇기 때문에 word embedding layer + positional encoding layer를 지날 때에 <PAD> token에 해당되는 벡터는 음의 무한대에 가까운 아주 작은 값을 갖도록 만든다.
앞서 배운 연산 순서라면 어텐션 스코어 함수는 소프트맥스 함수를 지나고, 그 후 Value 행렬과 곱해지게 된다. 그런데 현재 마스킹 위치에 매우 작은 음수 값이 들어가 있으므로 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0이 되어 단어 간 유사도를 구하는 일에 <PAD> 토큰이 반영되지 않게 된다.
아래 그림 참고.
1.1.4. FFNN 층과 Normalization

multi-head Attention 연산이 완료되면 아래와 같은 식으로 선형 연산과 비선형 연산이 진행된다.

추가적으로 Normalization이 진행된다.
Normalization은 각 층에서의 결과 분포가 비슷하게 유지될 수 있도록 하는 과정이다.
Multi-Head Attention과 FFNN층을 따라 올라가면서 언급하지 않은 것이 하나 있는데 Residual 학습이다. Residual = 잔차 학습은 층을 통과하기전 input을 통과한 후의 결과값에 더해주는 과정이다. 이는 층이 깊어지는 깊은 인공신경망에서 나타나는 gradient vanishing 문제를 없애기 위해 사용된다.
1.2. 잔차 연결(Residual connection)
잔차 학습, 잔차 연결 원리는 이전의 Resnet 구조에서 여러번 경험했으므로 간단하게만 짚고 넘어간다.

잔차 연결은 위 그림과 같이 input을 output 결과에 추가적으로 더해주는 일이다. 이것이 사용되는 이유는 간단하다. backpropogation을 진행할 때 우리는 직전층과의 gradient를 구하게 되고 이를 chain-rule에 따라서 loss에 대한 gradient를 구할 수 있다. 이 때 깊은 인공신경망에서는 보통 활성화 함수나 다른 요소에 의해서 gradient값이 매우매우 작아져 소멸하는 문제가 발생하곤 했다. 이런 문제를 해결하기 위해 residual 연결을 시도해서 gradient 계산(미분)을 진행하더라도 항상 gradient가 소실되지 않고 유지는 반드시 할 수 있게 할 수 있다.
위의 그림 같은 경우에는 x에 대해서 H(x)의 gradient를 구하려고 할 때 x에 대한 F(x) 미분값이 아주 작더라도 x에 대한 x의 미분값은 항상 1이기 때문에 gradient가 유지되는 효과를 거둘 수 있다.
지금 다루는 Transformer Attention기법에서는 아래와 같은 상황일 것이다.

1.3. Transformer의 Decoder
이번엔 Transformer의 Decoder 구조를 보자.
Transformer의 Decoder 또한 Encoder에서 다뤘던 Attention layer가 층층이 있고 Feed Forward를 거쳐 출력값을 내뱉는다.
1.3.1. Masked Multi-Head Self Attention
인코더에서 다뤘던 Multi-Head Self Attention과 매우 유사하다. 아니 유사함을 넘어서 거의 동일하다고 보면 된다. 다만 디코더에서는 Masked라는 부분이 추가된다. Transformer는 학습할 때 인코더와 디코더 모두에서 sequence를 순차적으로 넣는 것이 아니라 한번에 넣어주게 되는데, 이 때 디코더에서는 Self Attention 기법을 사용할 때 다음 시점의 입력 단어를 알고 있으면 안되기 때문에 Mask가 필요하다.

위와 같이 Self Attention 계산은 동일하지만 디코더의 경우에만 아래처럼 Mask가 필요하다는 것을 명심하자.

1.3.2. Encoder-Decoder Attention

이번에는 Decoder의 두번째 Attention layer인 Encoder-Decoder Attention이다. 이 Attention은 Seq2seq 기법에 Attention을 추가한 처음에 Naive하게 적용되었던 Attention과 동일하다. 디코더의 hidden state를 가지고 encoder의 hidden state들과 비교하여 Attention할 벡터(score)를 만들고 다시 디코더의 hidden state와 결합해 결과값을 추출한다.
다른 Attention과 모두 동일한 과정을 거치게 되므로 따로 설명하지는 않는다.
1.3.3. Importatnt Point
트랜스포머를 공부하면서 작동원리는 알게되었지만 세세하게 내부적으로 가지는 dimension이나 연산과정에 대해서는 이해하지 못했었다. 이후 소스코드를 보며 작동방식을 어느정도 알게 되었고 다시 헷갈릴 때 찾아볼 수 있게 기록하고자 한다.
- d_model은 embedding 차원이다. transformer는 이를 n_head로 나누어 각각을 Q, K, V로 확장(차원의 확장이 아니라 한 matrix로 여러 matrix를 만든다는 의미)시켜 만들고 각각 Attention 계산
- Q, K, V의 차원들은 논문에서는 모두 같지만 Q, K, V를 만드는 Wq, Wk, Wv 가중치들을 설정하면 다르게 차원을 변경할 수도 있다.
- Transformer의 input은 학습할 때와 추론할 때가 다르다. 학습할 때는 인코더, 디코더 모두 input을 sequence 전체를 통째로 넣고 추론할 때는 인코더에만 sequence를 한번에 넣으며 디코더에는 <sos>(시작 토큰)부터 넣어 뽑아낸 결과값을 다음 시점의 디코더에 넣어주는 방식으로 작동된다.
1.3.4. Attention을 병렬적으로 수행하는 이유
Transformer 기법에서는 embedding vector를 n_head로 나누어 각각 Attention을 수행한다. 즉, 병렬적으로 Attention을 각각 진행하고 다시 합치는데 하나의 embedding vector에 하나의 attention을 수행하지 않고 이렇게 수고를 들이는 이유는 뭘까?
위키독스를 참고하자면 답변은 아래와 같다.

병렬적으로 Attention을 수행하면 어떤 Attention은 어디에 집중하고 어떤 Attention은 다른 곳에 집중할 수도 있다. 아래의 예를 보자.

위에서 Attention을 설명하기 위해 가져왔던 사진이다. 오른쪽에서 'it'이라는 단어를 추측할 때 어떤 단어를 참고하여 추측할지 알아야하기 때문에 Attention을 사용한다고 했다. 이 때 Transformer 내부에서는 병렬적으로 Attention을 진행하기 때문에 어떤 Attention은 'animal', 어떤 Attention은 'The', 어떤 Attention은 'street'에 초점을 맞출 수 있다. 이런 것을 틀렸다고 생각하기 보단 논문의 저자들은 다양한 위치에서 다양한 관점을 가지는 장점으로 해석했다.
Attention을 직렬로 했을 때는 유추할 수 있는 결과값이 하나밖에 없었지만 병렬로 했을 때는 다양한 관점에서의 결과값을 보고 가장 높은 확률의 결과값을 선택할 수 있기에 더 신뢰도가 높아진다.
1.3.5. Reference
차원 관련 (특히 d_model, n_head) 헷갈리는 부분은 코드를 보면 좀 더 이해가 잘된다. 아래의 링크에서 Transformer를 구현하는 코드도 포함되어 있으니 참고하면 좋을 것 같다.
1) 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 Attentio ...
wikidocs.net
'ML & DL > NLP' 카테고리의 다른 글
| BERT와 KoBERT(Word-Piece Embedding, 코드리뷰) (0) | 2022.10.19 |
|---|---|
| NLP(자연어 처리) 입문 7 - Seq2Seq, Attention (0) | 2022.10.08 |
| NLP(자연어 처리) 입문 6 - RNN, LSTM (0) | 2022.10.07 |
| NLP(자연어 처리) 입문 5 - CNN 기반 텍스트 분류 (1) | 2022.10.05 |
| NLP(자연어 처리) 입문 4 - 텍스트 마이닝 (word2vec) (1) | 2022.10.04 |